利用深度学扩展双光子成像视场
来源:武汉光量科技有限公司
发布时间:2024-09-23 15:45:21
在生物医学研究领域,双光子成像技术因其高成像分辨率、大深度和强三维层析能力等优点,成为获取关键高分辨三维信息的重要手段。然而,传统双光子显微镜成像视场有限,通常在1mm以内,极大地限制了其在更广泛生物医学研究中的应用。
为拓展双光子显微镜的成像视场,研究人员尝试了多种方法。例如,通过设计特殊的扫描中继系统来减小大角度扫描引起的离轴像差,或自制高通量物镜来实现更大的成像视场。但这些方法往往实现难度大、成本高,难以在生物医学研究领域广泛推广。
近年来,一种通过自适应光学技术增加成像物镜可用视场的方法被提出。然而,该方法需要在光学系统中增加相位补偿器件,这增加了成像系统的光路复杂性与硬件成本。
在此背景下,来自曲阜师范大学、香港理工大学的李迟件团队提出了一种利用深度学替代自适应光学相位补偿从而扩展双光子成像视场的新方法。
深度学带来的新突破
商用物镜通常有一个厂商的成像视场,在该范围内,物镜像差可忽略,成像质量好;过该视场后,物镜像差急剧增大,成像质量严重劣化。
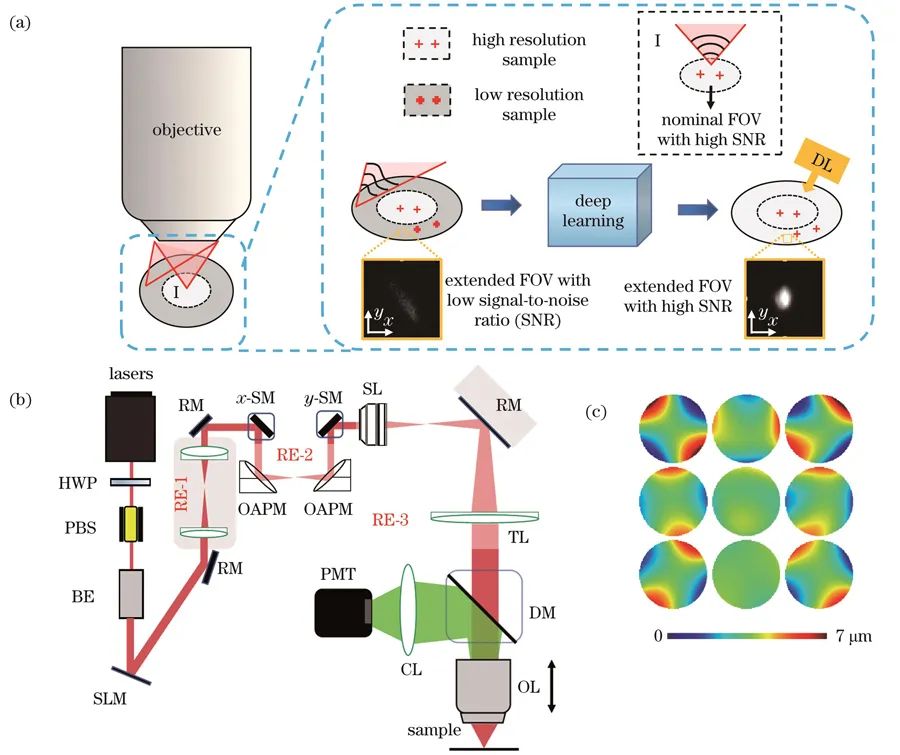
光学系统及成像原理。(a)深度学扩展双光子显微镜可用视场的原理图;(b)大视场双光子显微镜系统示意图(HWP:半波片;PBS:偏振分光棱镜;PMT:光电倍增管;RM:反射镜;BE:扩束器;SLM:空间光调制器;OAPM:离轴抛物面反射镜;SM:扫描振镜;SL:扫描透镜;TL:管透镜;DM:二向色镜;OL:物镜;CL:收集透镜);(c)测量得到的3×3个子区域的波前面
研究团队之前通过自适应光学方法使扩展视场的成像质量与信噪比接近于视场区域,*拓展了大视场物镜的可用视场。而本文所提方法通过采集扩展视场自适应光学校正前后的数据并使用改进网络框架进行训练,无需使用自适应光学相位补偿装置进行像差校正便可得到近似无像差的图像。
该方法具有以下优势:
-
无需复杂光学元件:无须使用复杂的自适应光学元件进行像差校正。
-
降低成本与提高便捷性:利用深度学替代硬件自适应光学补偿,不仅降低了系统成本,还实现了无须硬件自适应光学补偿的大视场成像,提高了系统的便捷性。
实验过程
在实验中,研究团队使用了大视场双光子显微系统,包括钛蓝宝石激光器、扩束器、中继镜、检流计、扫描振镜、物镜、二向分光镜、收集透镜和光电倍增管等。采用间接波前检测中的模式法实现像差测量和校正,将整个视场区域分为3×3个子区域进行分区校正,使用Zernike多项式的第5-15项进行像差计算,重复测量三次后取平均以保证测量准确度。
为提高神经网络的可靠性,研究团队对数据准备进行了两方面改进:
-
提高信噪比:对每组校正前后的图像各采集3张,并通过平均图像的灰度值来提高图像的信噪比。
-
匹配三维位置:将自适应光学技术校正前的图像作为参照,对校正后的图像进行X和Y方向的配准,将配准后的有效数据尺寸裁剪为1000pixel×1000pixel。
研究团队采用的基于U-Net改进的nBRAnet网络,具有U型对称结构,保留了多个跳跃连接结构。同时,引入残差结构以缓解反向传播造成的梯度爆炸和梯度消失,提高网络的*度和精度;引入轻量级的空间注意力机制以增强网络性能;移除了所有卷积块中的BN层以增强网络输出的图像质量。
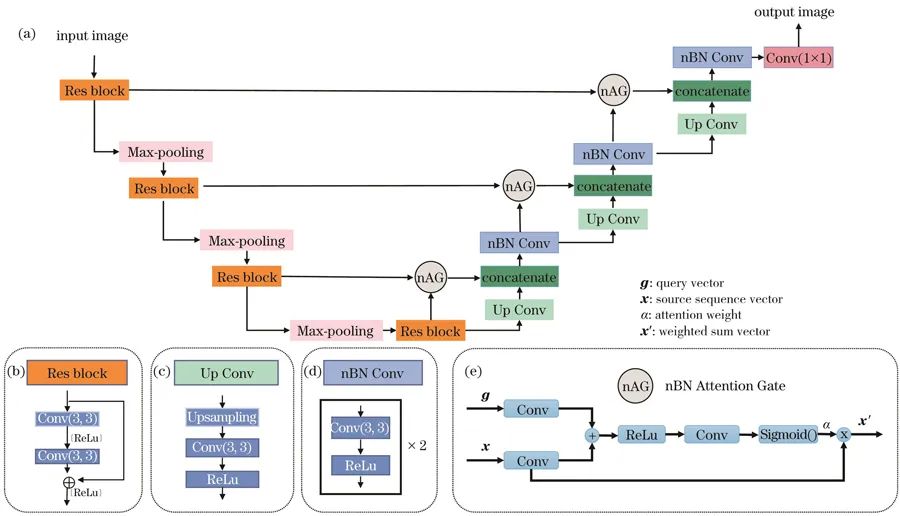
研究团队提出的nBRAnet网络结构。(a)改进的3层网络结构;(b)残差结构示意图;(c)上采样结构块;(d)改进的卷积块;
在网络训练设置方面,研究团队在Windows环境下进行,采用 PyTorch(Python3.7)编写代码,使用MATLAB代码处理图片,在桌面工作站上进行。数据集由荧光小球和离体生物样品经自适应光学校正前后的显微图像构成,网络模型输入图像和输出图像的尺寸均为1000pixel×1000pixel,分别取数据集的95%和5%用作训练集和测试集,利用网络输出与标签之间的均方误差作为损失函数来训练模型,同时利用反向传播算法Adam来优化网络,初始学速率为1×10-4。
实验结果
荧光小球实验:无论是在像差较小的视场区域,还是在具有较大离轴像差的扩展视场区域,研究团队所提网络均能较好地校正畸变的图像,证明了深度学技术可以替代硬件自适应光学像差校正技术扩展成像视场并实现畸变图像的校正。
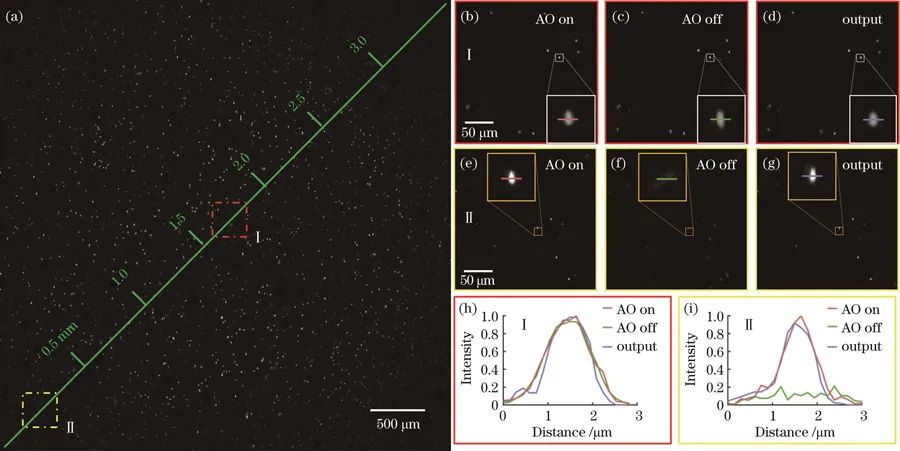
直径为1µm的荧光小球的大视场成像结果。(a)全视场荧光小球图像,视场尺寸为2.45mm×2.45mm;(b)~(d)区域经自适应光学校正前后的图像以及网络模型学得到的图像;(e)~(g)扩展区域经自适应光学校正前后的图像以及网络模型学得到的图像;(h)Ⅰ区域的强度曲线;(i)Ⅱ区域的强度曲线
生物样品实验:研究团队改进的网络框架可将Thy1-GFP样品扩展视场区域的分辨率和信噪比恢复至接近硬件自适应光学校正之后的结果,可有效扩展物镜的可用视场,使分辨率和荧光强度近似地恢复到硬件自适应光学校正后无像差时的水平。
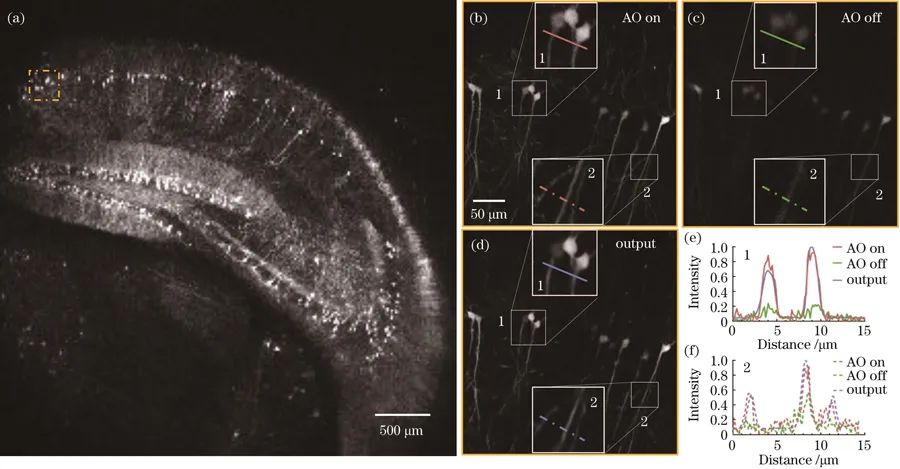
Thy1-GFP小鼠大脑切片的大视场成像结果。(a)全视场图像,视场尺寸为2.45mm×2.45mm;(b)虚线框区域扩展视场在自适应光学校正前的图像;(c)虚线框区域扩展视场在自适应光学校正后的图像;(d)深度学模型的图像增强结果;(e)(f)划线区域的强度对比
与深分辨率模型(VDSR)、传统的U-Net模型相比,研究团队的nBRAnet网络框架具有明显优势,VDSR的实验结果中含有大量噪声,U-Net的实验结果中丢失了一些细节信息,而研究团队的网络框架具有较高的PSNR值。
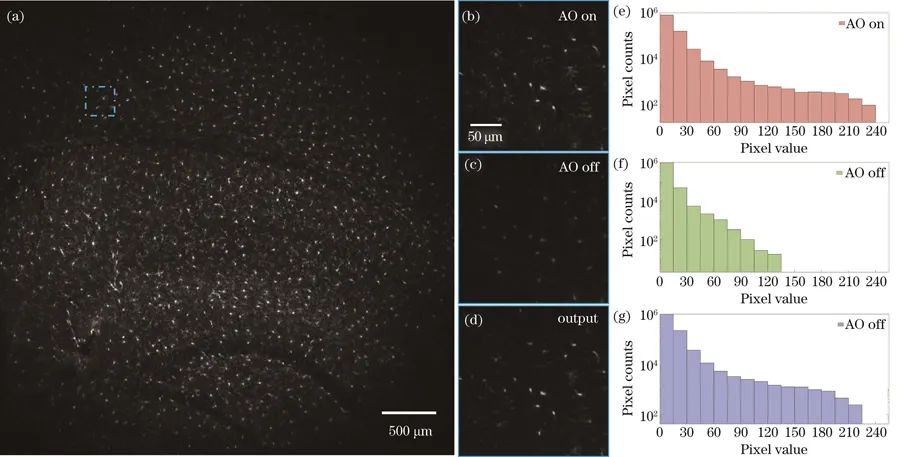
CX3CR1-GFP小鼠大脑切片中小胶质细胞的大视场成像。(a)全视场图像,视场尺寸为2.45mm×2.45mm;(b)虚线框区域扩展视场在自适应光学校正前的图像;(c)虚线框区域扩展视场在自适应光学校正后的图像;(d)所提深度学模型的图像增强结果;(e)~(g)灰度值直方图,分别对应(b)~(d)
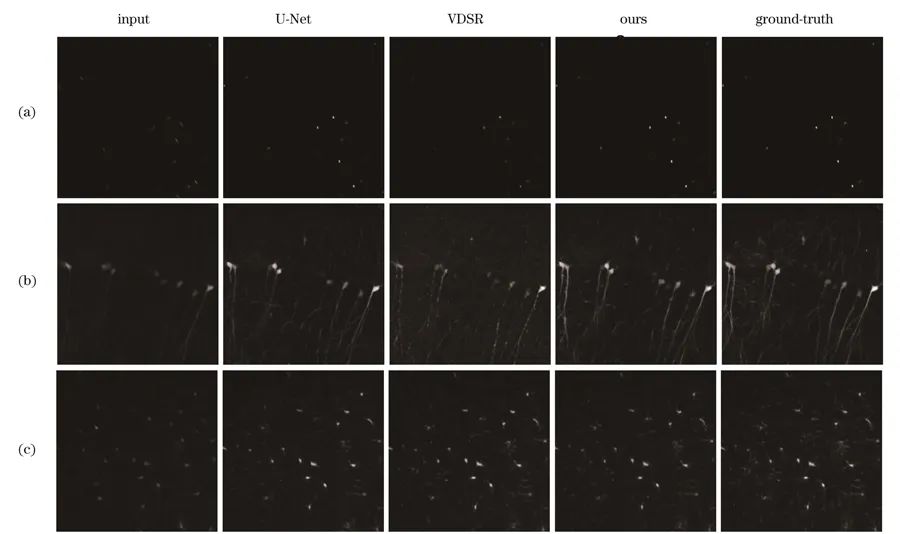
不同网络模型的输出结果。(a)荧光小球样品扩展视场的ROI区域;(b)Thy1-GFP样品扩展视场的ROI区域;(c)CX3CR1-GFP样品扩展视场的ROI区域
结与展望
研究团队提供了一种有效扩展双光子显微镜成像视场的新思路、新途径,利用深度学来扩展商业物镜的可用视场。经网络恢复后的扩展区域图像,无论是分辨率还是荧光强度,均能恢复到接近硬件自适应光学校正后无像差时的水平。该方法简化了操作,降低了系统的复杂度和成本,提高了成像分辨率及其拓展的通用性,具有较高的实用价值。
希望研究成果能为生物医学研究带来新的突破,为跨区域脑成像或全脑成像提供一种经济实用的方案。未来,我们将继续深入研究,不断完善这一技术,为推动生物医学研究的发展贡献更多力量。
声明:本文仅用作学术目的。文章来源于:李迟件, 姚靖, 高玉峰, 赖溥祥, 何悦之, 齐苏敏, 郑炜. 利用深度学扩展双光子成像视场[J]. 激光, 2023, 50(9): 0907107. Chijian Li, Jing Yao, Yufeng Gao, Puxiang Lai, Yuezhi He, Sumin Qi, Wei Zheng. Extending Field‑of‑View of Two‑Photon Microscopy Using Deep Learning[J]. Chinese Journal of Lasers, 2023, 50(9): 0907107.

温馨提示:为规避购买风险,建议您在购买产品前务必确认供应商资质及产品质量。
